
3D Vision – The frontier between AI and the physical reality
Convolutional Neural Networks (CNNs) have led to remarkable results in many Computer Vision (CV) tasks such as classification, recognition, segmentation, localization and scene understanding. Advancements in CNN architectures have been complemented with availability and expansion of annotated datasets as well as enhancement in processing power, especially with use of GPU.
Majority of these advances have been in the field of 2D vision, which mainly deals with insight extraction and analysis of images and videos. However, the reality, as we humans perceive it, consists of the three dimensions: horizontal, vertical and depth (x,y,z). Traditional cameras flatten the 3D world into a 2 dimensional representation (x,y). Though 2D imagery is useful for many CV tasks, it loses depth information and as a result lacks the full geometry of the sensed objects and scenes. With the recent advancements in robotics and autonomous vehicles, rich 3D information has proven to be quite valuable in assisting computers with human-like perception of the physical world.
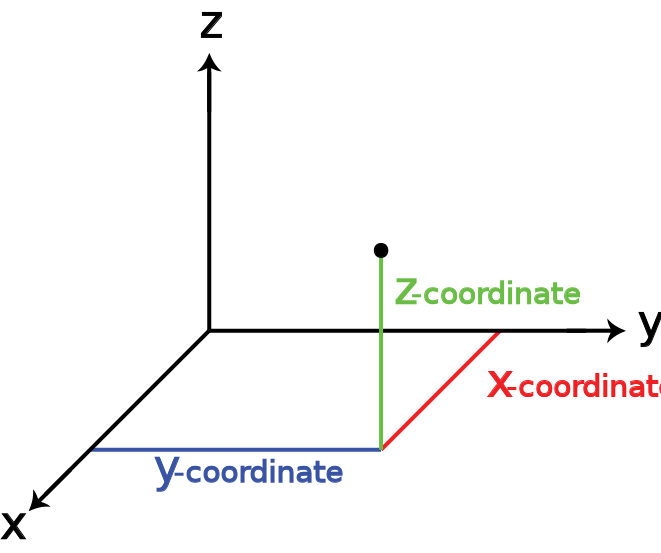
The current breakthroughs in the field of 3D vision are happening in the areas of 3D data acquisition devices, data representation techniques, neural network architectures, and 3D reconstruction of unseen viewpoints or as I like to call it Artificial Imagination.
The latest advances in 3D sensing technologies such as structured-light scanners and time-of-flight cameras have increased the availability and affordability of 3D data, hence, paving the way for the scientific community to develop the next generation of 3D vision models.
Unlike 2 dimensional images, which are mainly represented by stacking three RGB channels (red, green, blue), 3D data comes in with various forms and properties. The way a 3D data is presented is often the result of the 3D sensing device that was used to capture the data. Currently the four most promising data representation techniques for 3D models are RGB-D, Volumetric, MultiView, 3D Point Cloud and 3D mesh representations. Depending on the application, 3D sensing device and neural network architecture, the raw 3D data must be transformed into a proper 3D data representation.
There also exists a number of publicly available datasets of 3D data. Two of the prominent ones that rely on 3D CAD models and contain categorized objects are ShapeNet and ModelNet. Even though these datasets are comprehensive in terms of object categories and the quality of annotations, their data consists of virtually-constructed 3D images, thus do not generalize to real world objects.

The primary challenge in developing neural networks for 3D vision applications is capturing the full geometry and depth of the features present in the 3D data. Depending on the 3D data representation a specific Deep Learning (DL) architecture is required. RGB-D and MultiView datasets often rely on a Multi-Stream networks. For example an RGB-D dataset is best suited for a two stream model, where the RGB channels are separated from the depth and each runs through a 2D CNN separately for training. Features are then merged in the later layers of the network. Volumetric data on the other hand works best in models consisted of end-to-end 3D CNN and volumetric convulsions.
Another fascinating frontier in 3D Vision is the work being done on artificial imagination. Imagination plays an important part in how humans perceive and interact with the world. For example, imagine you enter a room and encounter a rectangular table, you might only see 3 legs of the table, often subconsciously our imagination constructs a full 3D model of that table, including the unseen parts, in this case the fourth leg. An exciting area of 3D vision is the reconstruction of 3D models from viewpoints that are not seen by the model. In a recent work, a group of scientists at DeepMind have published a research article and introduced the Generative Query Network (GQN). Currently this network is capable of predicting scene representations from previously unobserved viewpoints in a simulated environment.
The research in developing state-of-the-art neural net architectures for 3D vision applications is moving forward at an astounding pace. The business interest and the venture capital investments into the fields of autonomous vehicles and robotics are the primary drivers of the pace of innovation in this space.


{kind=link}
{kind=link}
{kind=link}
{kind=link}